Model predictive control (MPC) has become a popular strategy for electrical drive systems due to its flexible cost function design and fast dynamic response. However, the performance of finite-control-set MPC (FCS-MPC) heavily depends on the proper tuning of weighting factors in the cost function, especially when multiple conflicting objectives, such as torque ripple minimization, flux regulation, and switching frequency reduction—must be balanced. Conventional trial-and-error or heuristic tuning methods are time-consuming, lack adaptability, and often fail to maintain optimal performance under varying operating conditions.
In a study published in IEEE Transactions on Industrial Electronics, a research team led by Prof. WANG Fengxiang from Fujian Institute of Research on the Structure of Matter, Chinese Academy of Sciences, in collaboration with international researchers, proposes an improved reinforcement learning (RL) framework to automatically optimize the cost function weighting factors in multi-objective FCS-MPC for permanent magnet synchronous motor (PMSM) drives.
The researchers formulate the weighting factor tuning problem as a continuous-action RL task. A customized cost function is designed to incorporate torque tracking, flux regulation, and switching frequency minimization together with the weighting parameters to be optimized. To overcome the instability and overestimation bias commonly found in conventional deep deterministic policy gradient (DDPG) algorithms, the team adopts a twin delayed deep deterministic policy gradient (TD3) algorithm. The TD3 framework employs dual critic networks, delayed policy updates, and target policy smoothing, which significantly improve learning stability and convergence.
In the proposed scheme, the RL agent observes key system states that including dq-axis currents, tracking errors and normalized torque and flux deviations, which outputs two continuous actions representing the weighting factors for flux and switching frequency. A performance-oriented reward function is designed to penalize deviations from torque and flux references. The agent interacts with a high-fidelity PMSM simulation environment under diverse speed and load conditions to learn an optimal policy that balances multiple control objectives without requiring prior expert knowledge or manual intervention.
The proposed TD3-based adaptive weighting strategy eliminates manual tuning, adapts to varying operating conditions in real time, and achieves a balanced trade-off among multiple conflicting control objectives. The approach is computationally efficient for online deployment, as the learned policy only requires lightweight forward passes of the neural network, while the offline training is performed once on a standard GPU.
This research provides a practical and intelligent solution for multi-objective MPC in PMSM drives and can be extended to other power electronics and motor drive systems that require automatic cost function optimization.
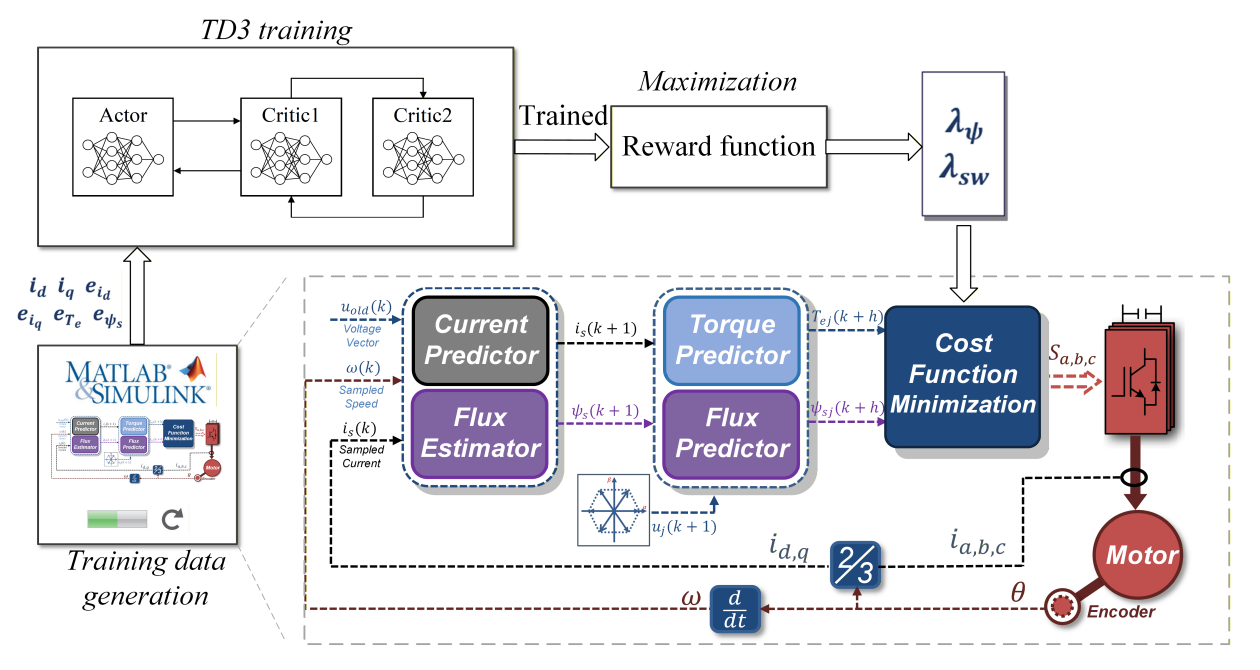
Simplified Implementation of the Research(Image by Prof. WANG’s group)
Contact:
Prof. WANG Fengxiang
Fujian Institute of Research on the Structure of Matter
Chinese Academy of Sciences
Email: fengxiang.wang@fjirsm.ac.cn